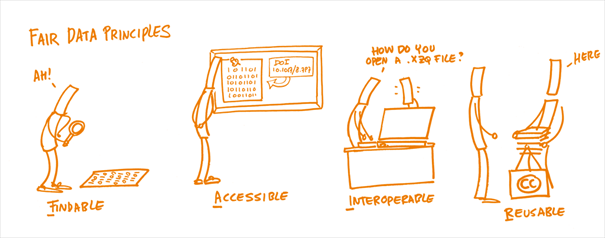
According to the FAIR principles data should be findable, accessible, interoperable and reusable to maximise its reuse potential. The guiding principles behind FAIR can be summarized as follows.
The CARE principles complement the FAIR principles as they provide guidelines how to ensure ethically sound use of data from indigenous communities. Formulated by the Global Indigenous Data Alliance, the CARE principles are as follows:

-
- Collective Benefit: Data ecosystems must be devised and operate in a manner that facilitates Indigenous Peoples in gaining advantages from the data
-
- Authority to control: Recognition of Indigenous Peoples’ rights and stakes in Indigenous data is imperative, and their authority to govern such data should be strengthened.
-
- Responsibility: Those engaged with Indigenous data bear a responsibility to disclose how these data are utilized to uphold Indigenous Peoples’ self-determination and mutual advantages.
-
- Ethics: The primary focus at all phases of the data life cycle and throughout the data ecosystem should be on the rights and well-being of Indigenous Peoples