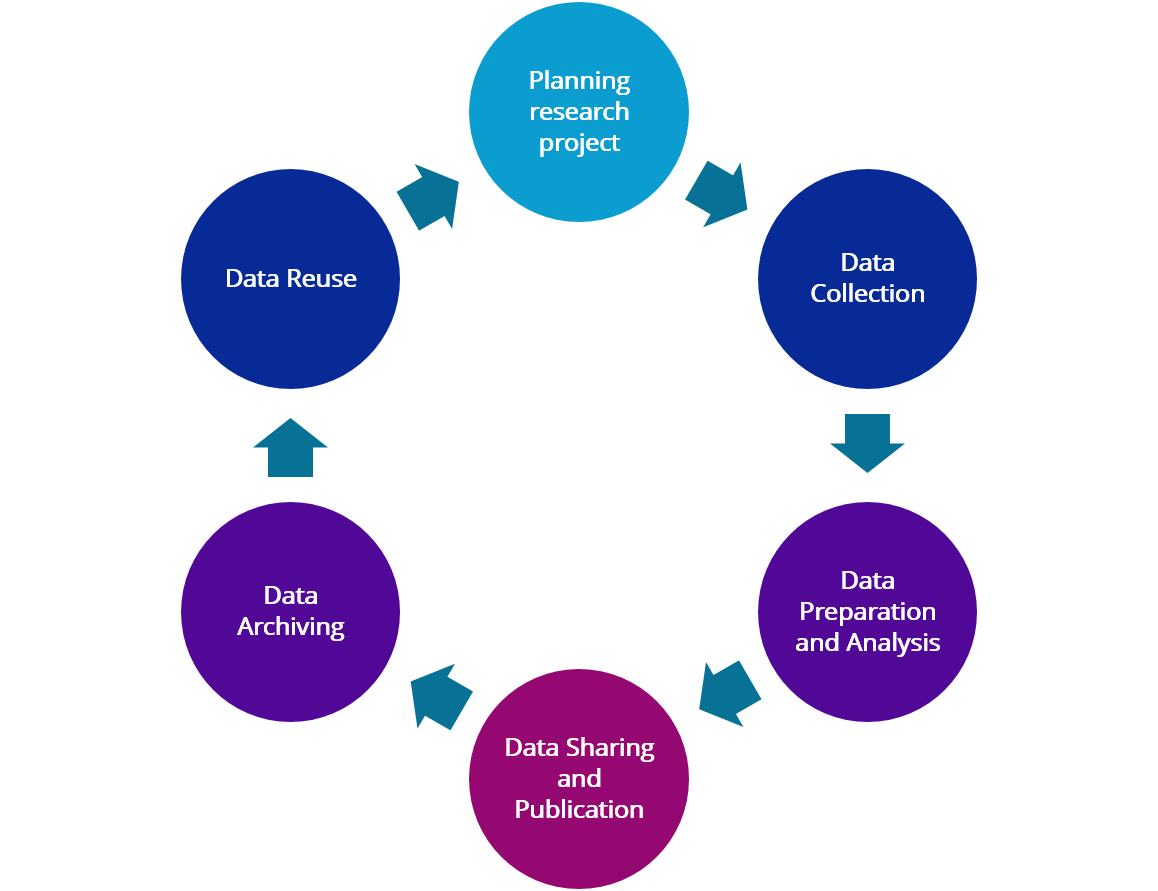
Documentation Platform
Welcome to the CLARIN-CH Documentation Platform. Here you will find useful information for the different steps of the data life-cycle. The platform offers best practices and resources that may be helpful for researchers to engage in FAIR-compliant data management in the context of CLARIN-CH.
Data Management Planning
Effective data management starts with the research design and involves planning ahead to encompass the entire data lifecycle. It is not only a necessary step in the research process, it is also a great benefit for you and the research community, if done right. Aligning data management practices with the FAIR principles and open data standards ensures transparency, accessibility, and the potential for broader collaboration within the research community.
Alongside, it’s valuable to address ethical and legal aspects early on to ensure compliance with relevant regulations. In principle, all CLARIN-CH institutions provide legal services and ethics committees, offering expertise to navigate complexities and establish sound consent mechanisms. In addition, the topic is being addressed by the CLARIN-CH working group on sensitive and personal data in the context of linguistics and social sciences to help researchers deal with questions that might come when working with language data.
Creating a Data Management Plan (DMP)
When receiving funding for a research project, researchers are required to submit a plan for research data management that is compliant with the FAIR principles. According to the SNSF, a data management plan should discuss the following topics:
- Data collection and documentation
- Ethics, legal and security issues
- Data storage and preservation
- Data sharing and reuse
It is crucial to include the resources and funding required for the implementation of the planned data management practices. The SNSF supports the preparation of data and their online storage with up to 10’000 CHF, on the condition that non-commercial service providers are used. SWISSUbase offers their data storing services for free. Other than the funding, resources such as the extra time required for careful data management and human resources should also be taken into account.
The DMP is meant to be used as a living document, i.e. it is good practice to periodically revise the data management plan throughout the research process. This can be done for example during project meetings held every six months, so that the plan becomes a documentation tool and a statement of quality assurance for your research data over the long term.
When dealing with sensitive data, special attention needs to be given to its organization and management. Several steps can be taken to ensure safe use of the data, i.e. a carefully drafted consent form and anonymization or de-identification of the data. More information on data protection, sensitive data and informed consent can be found on the following page: Data protection
Copyright issues should be addressed from the start: Who owns the copyright in the data? How can the data be shared, which kind of license is appropriate and are there any restrictions that might apply? If there are restrictions, how can we still make the data as FAIR as possible? To give an example, the data from the Swissdox@LiRI database cannot be shared directly due to copyright reasons. However, it is possible to share the queries that were used to download the data, and thus make it accessible for reuse. More information on copyright and Intellectual Property Rights issues can be found here.
Resources
The following resources may be helpful for researchers creating a data management plan:
- The Linguistic Research Infrastructure (LiRI) has published two data management plan examples. One illustrates a possible DMP for a language documentation project. The other is an example of a neuroimaging EEG project:
- The Swiss National Science Foundation (SNSF) provides a document with a list of questions that should be addressed in the DMP including good practices for each of them:
Further information from the SNF, including a checklist to identify FAIR data repositories, can be found in the DMP Guidelines for researchers.
The FORS Center has published a guide on “How to draft a DMP from the perspective of the social sciences, using the SNSF template”. It discusses each part of the DMP giving explanations and practical tips for SSH researchers applying for research funding in Switzerland.
A comprehensive guide on data management is offered by CESSDA, the Consortium of European Social Science Data Archives:
It was designed to help researchers make their research data FAIR and includes well-structured, detailed information for each step of the data lifecycle.
- Several CLARIN-CH institutions offer information and services that help with creating a DMP:
Let us know if your institution has a similar platform that could be useful for other CLARIN-CH members!
Data collection

Data build the foundation of research – carefully planning and carrying out the data collection process is therefore crucial for your research project. This will ensure obtaining high-quality, reliable data that aligns with your research objectives.
Thoughtful planning involves selecting appropriate methods, considering ethical implications and legal issues, as well as anticipating potential challenges. A well-executed data collection phase thus not only streamlines subsequent analysis but also lays the groundwork for drawing meaningful conclusions. Before collecting new data, you should always check if there are existing data sets that are suitable for your research endeavour. Find out more on how to discover and re-use data here.
Data Types
Research data can take on various forms and for each of them, the data collection process is different. Classifications can be made according to various different characteristics, one of them being the data type:
- Textual Data: Text corpora, annotated texts, parallel corpora, learner corpora, etc.
- Phonetic Data: Audio recordings and phonetic transcriptions
- Lexical Data: Dictionaries, language models, lexica, glossaries, wordlists, conceptual resources (e.g. WordNet/FrameNet), etc.
- Syntactic Data: Treebanks, dependency parsed texts, etc.
- Semantic Data: Semantic annotations, ontologies, word embeddings, etc.
- Discourse Data: Conversational transcripts, digital discourse, etc.
- Experimental Data: Psycholinguistic experiments, eye-tracking, brain activity recordings, etc.
- Language Variation Data: Dialectal data, sociolinguistic surveys, etc.
- Multimodal Data: Video recordings, gesture annotations, etc.
Documenting data collection
Just as important as the creation of the research data itself is the metadata that contextualizes it, supporting the interpretation of the research data and thus fostering transparency as well as reproducibility in the research field.
A number of questions about data collection should be answered by the documentation of your data:
- For what purpose was the data created?
Describe the project history, its aims, objectives, concepts and hypotheses. - What does the dataset contain?
Give information on the type of data (interviews, images, questionnaires, etc.), file size, file formats used and relationships between files. - How was the data collected?
Describe the data collection method and all sources the data come from. - Who collected the data and when?
Indicate the name(s) of the data collector(s), date of data collection and geographical coverage of the data.
Source: CESSDA Data Management Expert Guide
While these questions address general information at the project level, it is also important to be specific about the data objects themselves. Depending on whether you are dealing with qualitative or quantitative data, different requirements may apply.
- Documentation of qualitative data should give background information and contextualize how it was created.
Documentation of quantitative data should describe the data file (e.g. file format, size, processing scripts, etc.) and the variables that are used in it.
Data processing and analysis
As every field has its own ways of analysing data, the best practices for data processing heavily depend on the methods you choose for your research. However, some things are relevant for all researchers:
- Keep several copies of your data
It is important to have both physical and virtual copies of your research data as back-up. It is also advisable to work with a systematic versioning system. - Ensure the integrity of your data
Take measures to make sure your data is accurate, consistent and complete, e.g. using automation to prevent mistakes arising from manually entered data. Chapter 3 in the CESSDA Data Management Expert Guide contains a detailed guide on this topic: Data entry and integrity - Choose interoperable file formats
When processing data, you may have to decide on file formats for the output of your analysis. Make sure to use file formats that have high compatibility and are widely used (see Standard data formats). - Be careful with personal/sensitive data
If your data contains personal information, use anonymization / de-identification procedures before carrying out data analysis (see Data protection). - Implement data security measures
Make sure your data is stored securely and can only be accessed by authorized users (see Data access and security).
Resources
We recommend familiarizing yourself with the following tools that support researchers in processing their data:
SSH Open Marketplace
The SSH Open Marketplace is a European discovery platform for resources from the Social Sciences and Humanities (SSH) field. It does not only offer language resources but also workflows that are carefully described in a step-by-step guide. For example, you can find a workflow on linguistic annotation of corpora here.
SSH Open Marketplace
CLARIN Tools
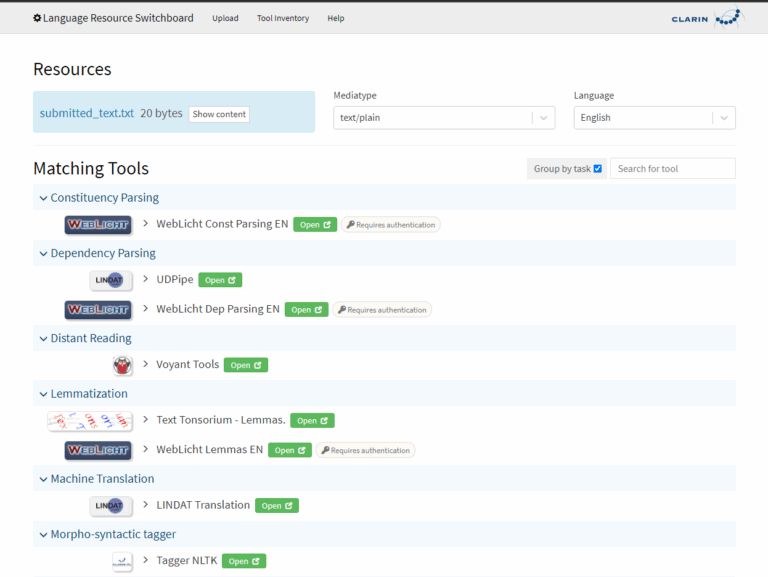
CLARIN centers offer a wide variety of tools that help researchers explore and analyse language data. An interface has been created that combines all these tools:
The CLARIN Language Resource Switchboard is a tool that helps you to find a matching language processing web application for your data. After uploading a file or entering a URL, you can select which task to perform. The Switchboard will then provide you with a list of available CLARIN tools to analyze the input.
Have you developed your own tool which could be useful for other researchers? You can add it to the Switchboard Tool Registry. Find out more about sharing your tools here.

forschungsdaten.info
This website designed for researchers from DACH countries discusses a lot of topics on research data management in great detail. You might find specific information that is relevant for your research project, for example here:
- Tools for Research Data Management
- Working with Large Amounts of Data
- Visualizing Data
- Data Transfer When Working with Sensitive Data
Publish and archive the data with LaRS@SWISSUbase
Include the corpus on the Linguistic Corpus Platform (LCP)
Add the corpus to the SSH Open Marketplace
Add your corpus on the webpage of the CLARIN Resource Families
Add your tool to the CLARIN Switchboard
Add your tool to the SSH Open Marketplace
Add your tool on the webpage of the CLARIN Resource Families
Add your lexical resource to the SSH Open Marketplace
Add your lexical resource on the webpage of the CLARIN Resource Families
Data archiving
What happens with research data after the completion of a project?
This question should already be addressed in the data management plan. It is a crucial step of the research process: Archiving ensures the preservation and accessibility of valuable data in the long-term, facilitates transparency in methodology, and enables the reproducibility of findings by allowing other researchers to scrutinize and build upon previous work.
However, these benefits only play out if the data are archived according to the FAIR and CARE principles. In some cases it can be difficult to stick to these principles, as they may be in conflict with copyright or data protection. More information on how to handle sensitive data and copyright issues can be found on the following pages: Data protection & Copyright.
I want to archive my research data. How can I find a suitable repository?
As a researcher at a CLARIN-CH institution you have several options to deposit your data:
- SWISSUbase is a national repository for research data providing researchers with a solution for long-term storage of their data. The linguistic data service unit LaRS (Language Repository of Switzerland) is an important part of CLARIN-CH, as it is a reliable way to store your research data in Switzerland and is tailored to language resources thanks to a discipline-specific metadata scheme which can easily be applied to your data.
- DaSCH is the Swiss National Data and Service Center for the Humanities, providing expertise in research data management and long-term preservation. It was established by the Digital Humanities Lab at the University of Basel and the Swiss Academy of Humanities and Social Sciences (SAGW) in 2017 and operates as a national research infrastructure promoting Open Data since 2021.
- Many CLARIN-CH institutions offer their own data repository, such as BORIS (Bern Open Repository and Information System). University libraries usually provide archiving services as well and more recently, data steward services have been established in various institutions, who will be able to help you when choosing a repository.
- Find a repository in the list of non-commercial, FAIR-compliant data repositories recommended by the Swiss National Science Foundation (SNSF):
- Most research data repositories are also listed on re3data.org, a global registry of research data repositories that aims at promoting a culture of sharing, increased access and better visibility of research data. It can be used as a discovery platform for data repositories, offering a short description and comprehensive metadata on each of the listed repositories, including database access and the standards that it uses.
How to publish sensitive and personal data?
When your research data contains sensitive and personal data, several measures need to be taken for publication. From informed consent to de-identification and controlled access, there are many options to ensure your data is published securely. Learn more on the following pages:
Data access and security Data protection
Not every research endeavour needs to be addressed by creating new data. In fact, reusing data is an effective way to leverage what has already been done in the research community. The R in FAIR is thus important to keep in mind when planning your research endeavour. You can skip the time-consuming step of data collection and move on to data analysis, thereby saving resources and acknowledging other researchers’ work.