Federated Content Search (FCS)
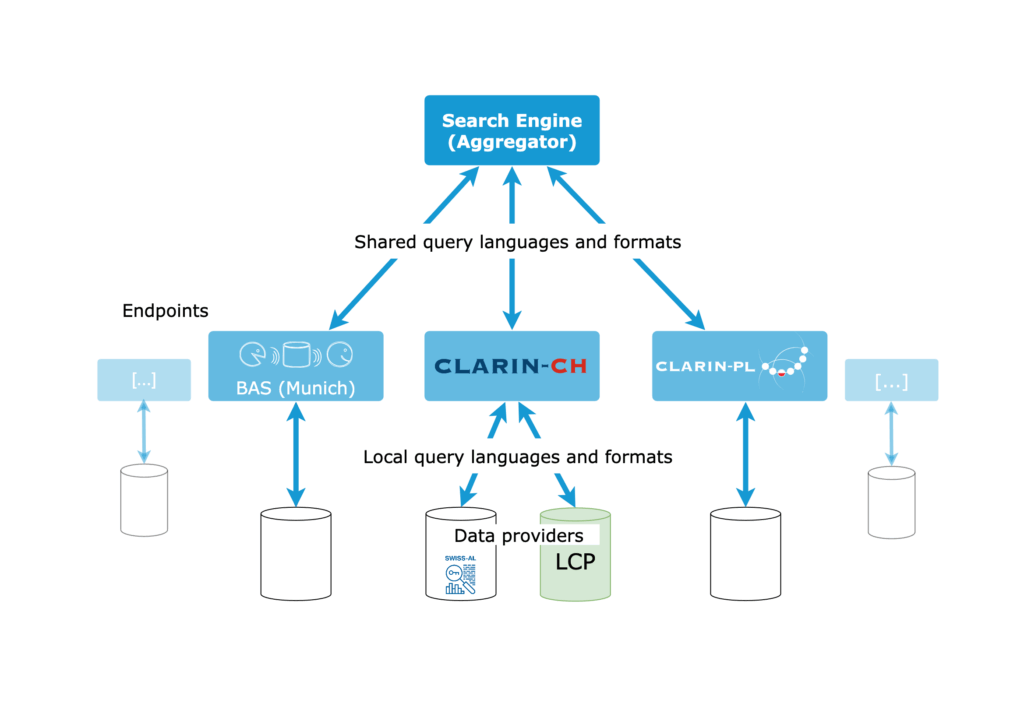
CLARIN has developed a search engine that enables users to query the local search engines of multiple CLARIN centres simultaneously. The centres host the data but with the Federated Content Search (FCS) more researchers are able to query local language resources. The FCS communicates with endpoints implemented by the centres which in turn activate the local search engines. This makes it possible to look through all the textual data offered by the individual centres. The user can display results through an aggregator which offers a content search that offers filters to display results for specific keywords, languages and resources.
CLARIN-CH content search
The Swiss node of CLARIN is implementing its own content search. Researchers at the ZHAW Digital Discourse Lab in collaboration with the UZH Linguistic Research Infrastructure have developed a federated search engine similar to the FCS aggregator from CLARIN with which users can query Swiss language resources specifically.
The search engine is still under construction. However, a first version is already available here. The aggregator provides access to public corpora from:
For more information on the new CLARIN-CH content search, you can visit its github.
What problem is FCS solving?
By querying local search engines through endpoints that can translate the individual query language into a shared query language, FCS simplifies and enhances the process of finding relevant textual data. It is easier because instead of looking through multiple datasets one-by-one, users only have to query one aggregator that is able to pool results from multiple endpoints containing multiple search engines. Furthermore, it may enhance the search as it can look through hundreds of resources simultaneously, which is a time-consuming effort when tried manually.
Legal issues can make it impossible for some collections to be copied to another location. However, by pointing to the resource instead of hosting it, FCS circumvents that problem. Federating instead of hosting the content is also more storage efficient as the size of many datasets nowadays can become costly for a centralized system. Another advantage of FCS over other search engines constitutes the fact that it can query and display results for search engines that are annotated in a collection-specific manner.
However, FCS also comes with limitations. Other than most local searches, the federated content search is missing the ranking feature and is unable to handle customized annotations. FCS is meant to be interoperable returning results from dozens of centres, thus its ability to handle complex queries is limited. Nonetheless, FCS has proven to be a helpful tool to quickly get an overview of the local search engines that host relevant data and to know where to continue with a more specialized search. Furthermore, its power lies in its size. Big engines such as FCS lend themselves ideally for statistical analysis.
How does FCS work?
The FCS specification is made up of two spheres. On the one hand, the shared infrastructure consists of the aggregator or search portal that forwards queries to endpoints and presents the results. On the other hand, a number of CLARIN institutions provide endpoints that use a transport protocol to translate from the shared query format to specific local query formats depending on which local search engine is queried. These search engines provide query results for local resources which are translated into a readable XML format by the endpoints and returned to the aggregator where they are displayed for the user.
From query to result
The user query
Whenever a user types a keyword or utterance into the search bar from the decentralized search engine and applies filters, it is reformulated into an SRU/CQL format. This is a URL that contains the specifications of the query in the CQL (Contextual Query Language) format. The aggregator sends the URL to the specified endpoints.
Endpoint translation
The URL sent by the aggregator is received by the endpoint which maps the CQL query to the query format the local search engines, it is connected to, use.
Endpoint execution
After reformatting the query, the endpoint executes the search and collects the hits it receives from the local search engines. Once it has completed its search, it returns the results to the aggregator in an XML format.
Aggregator display
In most cases, multiple endpoints have gathered results from even more local search engines. The aggregator receives the results from the endpoints and displays them for the user.