Content
CLARIN-CH Survey on Standard Data Formats
CLARIN-CH carried out a community survey to determine which data formats are most widely accepted among the research community working with language data. It aimed to gather inputs from various linguistic subfields in order to represent different types of linguistic data. The results served as a basis to the recommendations provided by CLARIN-CH to the CLARIN Standards Information System.
Main takeaways
- Open formats such as XML, CSV or JSON are preferred over proprietary formats such as DOC, PDF or SPSS.
- Specific recommendations and plotted survey results for each data type can be found below
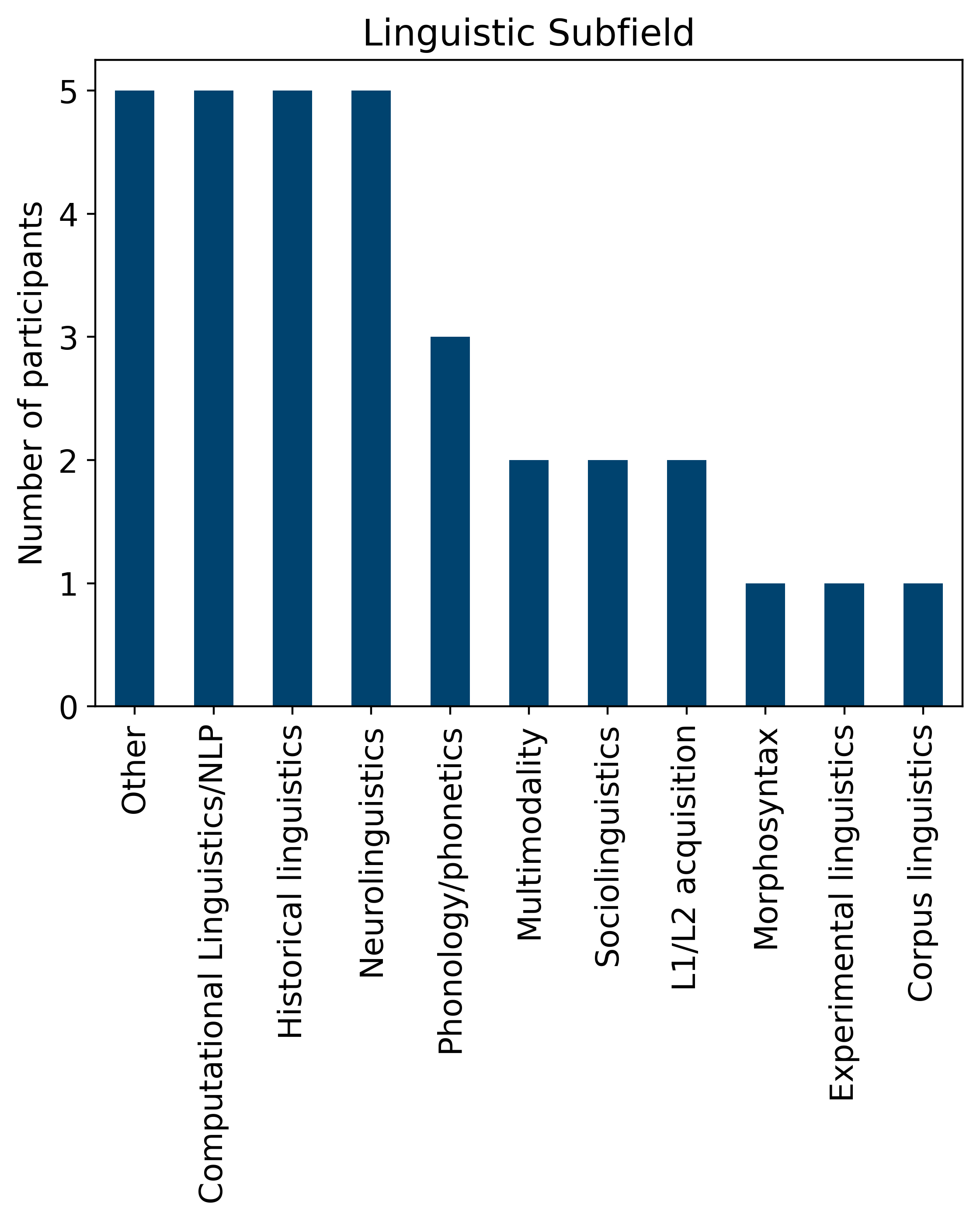
- Participation varied significantly by linguistic subfields: not all domains were equally well represented in the survey responses
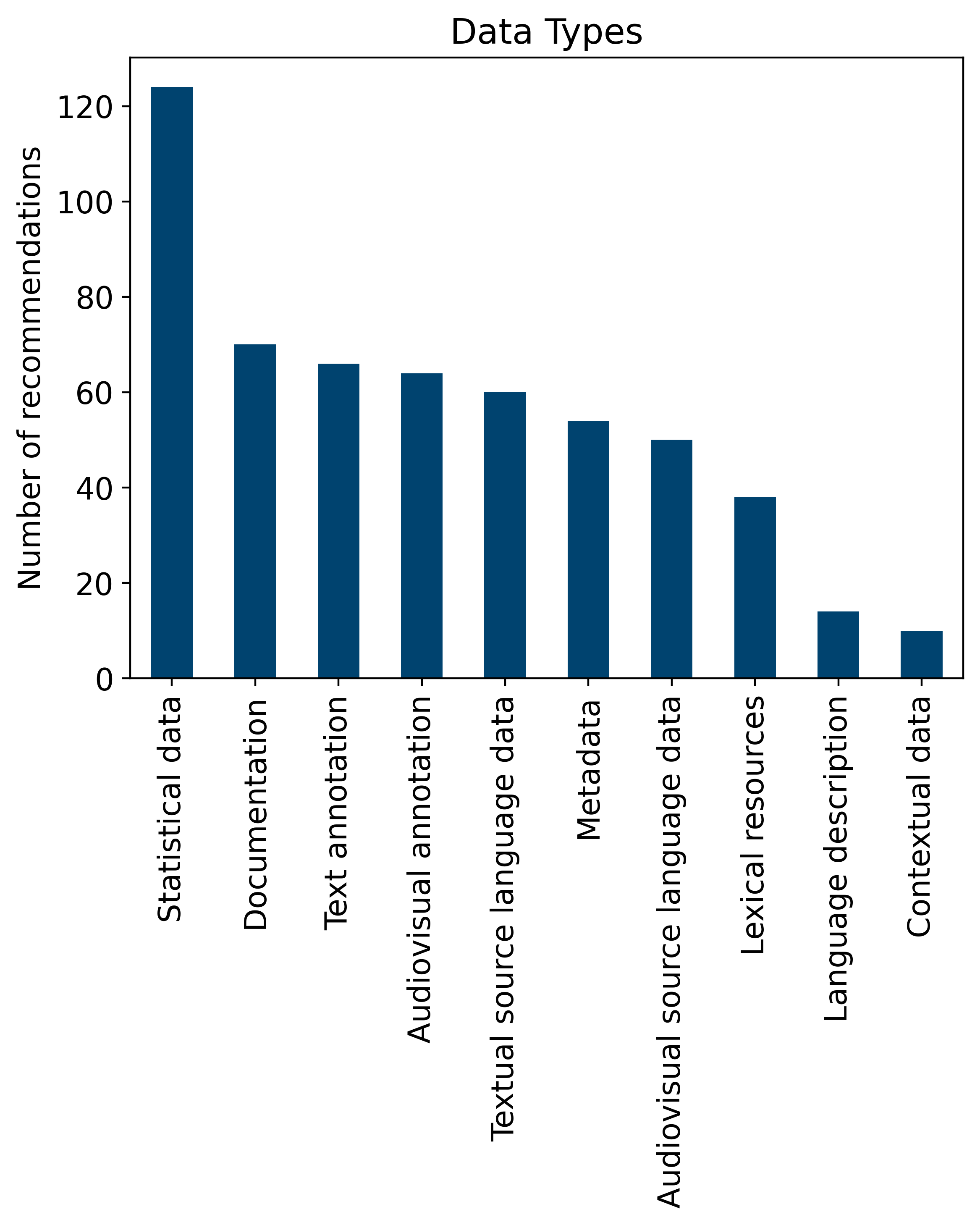
- The most recommendations were given for statistical data, suggesting that the CLARIN-CH community brings together ample expertise in quantitative research
The survey results provide an overview of the formats recommended for different data types and the linguistic subfields represented in the survey. As shown in the Data Types plot (see below), statistical data received the highest number of recommendations by far, reflecting shifting preference for quantitative studies in linguistic research in Switzerland.
The Linguistic Subfield plot shows a broad range of expertise among the survey participants, with the largest group from computational linguistics, NLP, and historical linguistics, followed closely by neurolinguistics and phonology/phonetics. This diversity of subfields ensures that the recommendations gathered from the survey are well-rounded and reflect the needs of various linguistic disciplines.
Results by data types
To see the results, click on the data types you are interested in:
Text annotation
Text annotation recommendations show how researchers are discontent with the usage of PDF. PDFs might be a good option to inspect individual files but those are hard to read and to be used in any other software. Apart from that, PDFs lack any specific structure apart from the one imposed by formatting and thus, more rigorous formats are preferred, such as TEI, CoNLL-U and XML. JSON could be indicated only as acceptable because it is less familiar and less used by researchers but it's a powerful format to represent text annotation, even though other options are probably more suited for it.
- Recommended: TEI, CoNLL-U, XML
- Acceptable: JSON
- Discouraged: PDF

Audiovisual Annotation
Audiovisual annotation formats reflect a preference for specialized formats tailored for multimedia data. EAF (ELAN Annotation Format) and TextGrid (used by Praat) are highly recommended due to their strong support for time-aligned annotations, essential for audiovisual material. These formats are well-suited for linguists and researchers working with video or audio recordings as they allow precise and structured annotations over time segments.
On the other hand, DOCX and plainText formats are discouraged because they lack the necessary structural complexity to handle time-based data effectively. XML, though not as popular for this particular use case, is still a recommended format due to its flexibility in representing hierarchical structures, which could be leveraged for audiovisual data, albeit less intuitively than EAF or TextGrid.
- Recommended: EAF, TextGrid, XML
- Discouraged: DOCX, plainText

Audiovisual source language data
The survey results for audiovisual source language data formats reveal clear preferences in the linguistics research community. MP4 emerges as the most recommended format, likely due to its widespread compatibility and ability to handle both audio and video content. WAVE and MPEG formats are also strongly recommended, suggesting a preference for high-quality, lossless audio when video is not required.
Interestingly, while MP3 and OGG are deemed acceptable, they are not as highly recommended as the other formats. This could be due to their lossy compression, which may impact the quality of linguistic analysis. The recommendations appear to prioritize formats that preserve audio fidelity and offer broad compatibility across different systems and software used in linguistic research.
- Recommended: MP4, WAV, MPEG
- Acceptable: MP3, OGG

Documentation
Documentation reflects the general trend of preference for non-proprietary formats and for formats that have at least some type of structure imposed. The first criteria discards DOC and RTF. The latter criteria discards ODT.
Notably, we do not have any format that is recommended but XML and HTML are marked as acceptable, as they could contain different types of documentation with some structure on top of it. But even so, they are not judged to be the optimal formats.
- Discouraged: DOC, RTF, ODT
- Acceptable: XML, HTML

Lexical resources
There is little debate with recommended formats for lexical resources. CSV is clearly an easy-to-use format and it is suitable for lexical data. XML might allow for unnecessary high levels of complexity for lexical data but it could come useful for certain datasets.
FLEx and SQL are good for the same purposes but they are less familiar to general community and, because of that, less easy to work with because tools developed by researchers are often not adapted to work with those formats.
- Recommended: CSV, XML
- Acceptable: FLEx, SQL

Statistical data
Due to strong quantitative orientation of Swiss researchers, R and Python are becoming increasingly popular tools for statistical analysis. They are versatile, easy to learn programming languages with a lot of packages developed by the community.
SPSS and SAS may have an added advantage of having a GUI but at the same time, both require subscription and are more limited in their functionality. Thus, these two options are inappropriate for any novel methodological work.
- Recommended: R, py
- Discouraged: SPSS, SAS

Metadata
The survey results for metadata formats in linguistic research reveal a diverse range of preferences and recommendations. Notably, structured and machine-readable formats are favored, with JSON, TEIHeader, and DC XML emerging as the recommended options. These formats likely gain preference due to their ability to represent complex metadata structures and their compatibility with various linguistic tools and databases. XML, BibTeX, and CSV are deemed acceptable, suggesting they are usable but may have limitations for certain metadata applications.
DOC format is strongly discouraged, likely due to its lack of structured data representation, potential compatibility issues and its proprietary status. This recommendation pattern underscores the importance of using formats that facilitate easy data exchange, integration, and analysis in linguistic metadata management.
- Recommended: JSON, TEIHeader, DC XML
- Acceptable: XML, BibTeX, CSV
- Discouraged: DOC

Textual source language data
The survey results for textual source language data formats in linguistics research show a clear preference for structured and machine-readable formats. XML stands out as the most frequently recommended format, likely due to its flexibility in representing complex linguistic data structures and general familiarity with the format.
Other recommended formats include CoNLL-U, JSON, and plainText, suggesting a preference for formats that are either standardized for linguistic annotations (CoNLL-U) or easily parseable (JSON and plainText). HTML is deemed acceptable, possibly due to its widespread use in web-based content. Notably, several formats are discouraged, including DOC, PDF, Markdown, and ODT. This discouragement likely stems from issues with data extraction, lack of standardization, or difficulties in automated processing for linguistic analysis.
- Recommended: XML, CoNLL-U, JSON, plainText
- Acceptable: HTML
- Discouraged: DOC, PDF, Markdown, ODT

The CLARIN Standards Information System serves to promote interoperability and re-usability of research data by aggregating and visualizing the recommendations for data deposition formats specified by CLARIN centres all around Europe. If you are interested in seeing what other CLARIN centers recommended, you can consult the following page:
We would like to thank all researchers who participated for sharing their knowledge and expertise with us. If you did not have the chance to contribute but would still like to give your inputs, do not hesitate to get in touch with us.